
We are breaking the interspecies understanding barrier with a fundamentally new approach.
We take a modern, AI-first approach to studying animal communication, leveraging advances in large-scale models, multimodal learning, and vast datasets to unlock the hidden languages of the natural world.
Our research operates in a virtuous cycle: AI facilitates scientific discovery in animal communication, and those discoveries refine our AI models with greater capabilities.

Across the Tree of Life
Trained on massive data sets across human speech and music, bioacoustic data and environmental sounds, our models learn foundational representations of bioacoustic signals.
This makes them generalizable across tasks and species. Whether studying birds or whales or jumping spiders, our large animal language models help researchers automatically detect, classify, and find new answers in massive unlabeled ethology datasets.

NatureLM-audio: Our Flagship Model
NatureLM-audio is the world’s first large audio-language model for animal sounds. Trained on a vast and diverse dataset spanning human speech, music, and bioacoustics, it brings powerful AI capabilities to the study of animal communication.
With NatureLM-Audio, researchers can:
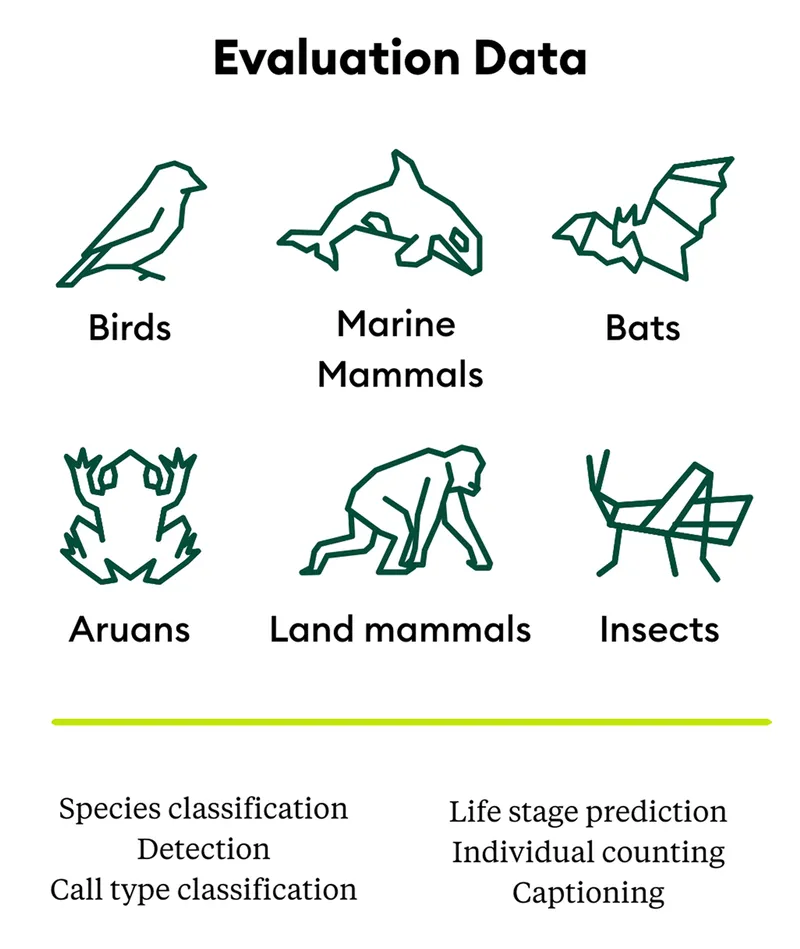
- Detect and classify thousands of species and vocalizations across diverse taxa
- Recognize species it has never encountered before with better than random accuracy
- Answer complex questions about bioacoustic data using natural language.
- Analyze massive datasets in minutes rather than months, accelerating research at an unprecedented scale.
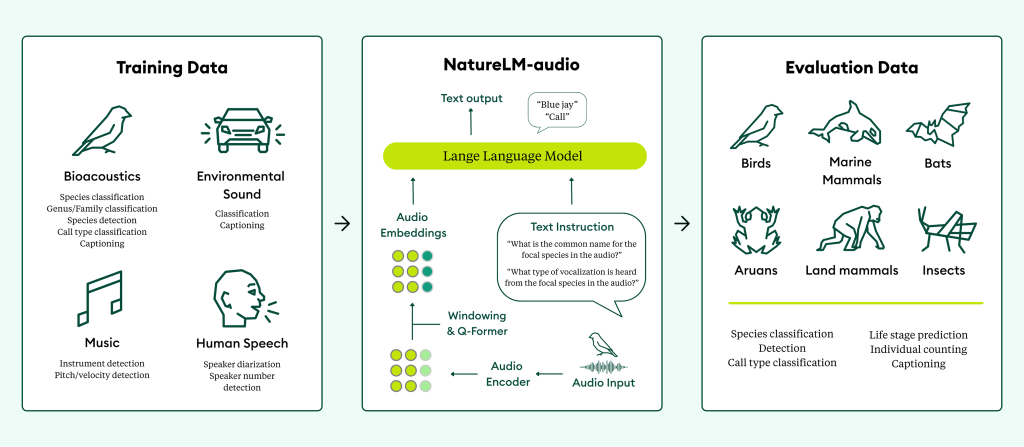

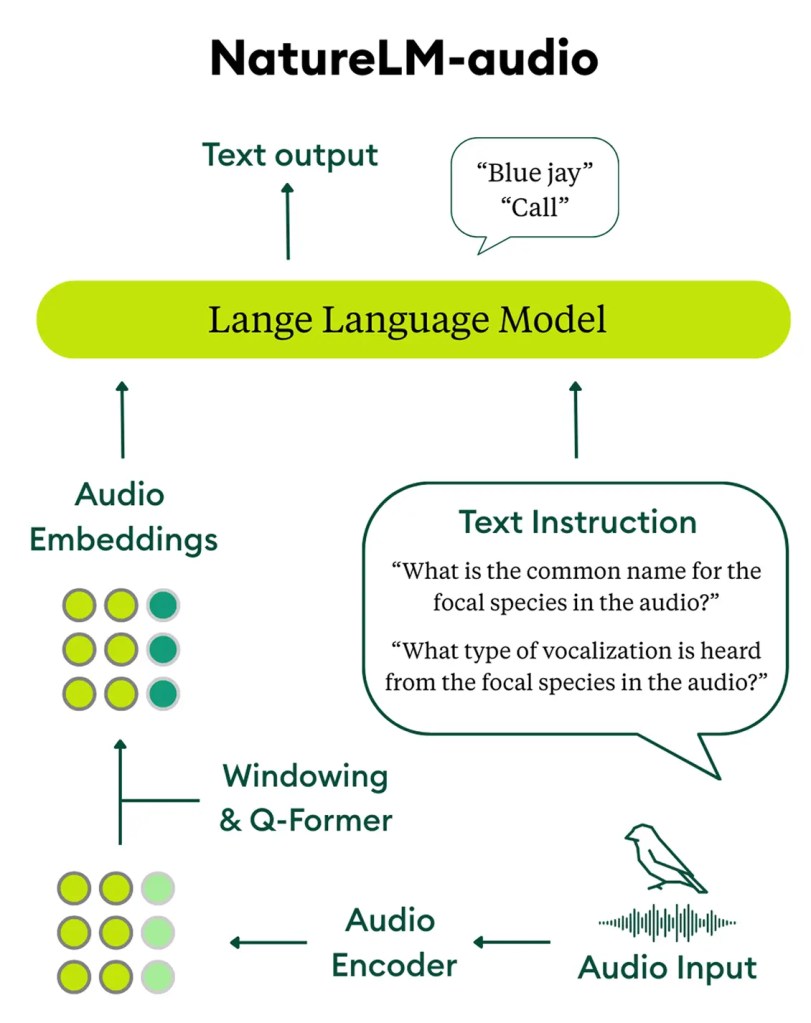
NatureLM-audio exhibits few-shot learning capabilities at inference time, allowing it to generalize to new tasks without needing to be retrained. Instead of needing to fine-tune the model on a new dataset, users can prompt it with just a few examples of a new task, and the model can generate meaningful responses based on existing knowledge.
NatureLM-audio also demonstrates emergent properties like the ability to count the number of individuals in a recording, identify distress and affiliative calls, and classify new vocalizations—without explicit training. It also shows promising domain transfer from human speech to animal communication, supporting our hypothesis that shared representations in AI can help decode animal languages.
Decode: Applied AI for Discovery
We apply frontier AI to the study of how animals communicate and perceive the world.
Task- or Species-Specific: We work with ethologists studying animal communication to build tools for the study of specific species that will generalize to other species and improve our core models.
Decode Questions Only AI Can Answer: We design large-scale Decode projects that seek to answer questions that have been impossible to ask because of the size and complexity of the data sets.
Foundational Tools for Bioacoustics
We apply AI principles to core bioacoustic tasks like detection, classification, and dataset processing, ensuring that scientists have powerful, scalable tools to accelerate their work:
- Voxaboxen – A collaborative annotation platform for labeling and organizing animal vocalizations.
- Biodenoising – An AI-driven tool for denoising bioacoustic recordings, improving signal clarity without the need for clean training data.
- AVES – A self-supervised foundation model designed to analyze and classify animal vocalizations across diverse species.
- BirdAVES – A specialized extension of AVES optimized for bird vocalizations, improving performance by 20% on bird datasets.
We’ve also developed the first benchmarks for applying AI to animal communication research. These benchmarks provide researchers with high-quality datasets and rigorous evaluation metrics, ensuring that AI-driven insights into animal vocalizations and behavior are both reliable and reproducible.
- BEANS – The first benchmark for bioacoustic classification, providing standardized datasets for evaluating AI models on animal sound recognition.
- BEBE – A benchmark for analyzing animal movement using bio-logger data, enabling standardized evaluation of machine learning methods in movement ecology.
- Beans-ZERO – A specialized extension of BEANS for zero-shot learning, testing how well AI models generalize to species and vocalizations they haven’t encountered before.